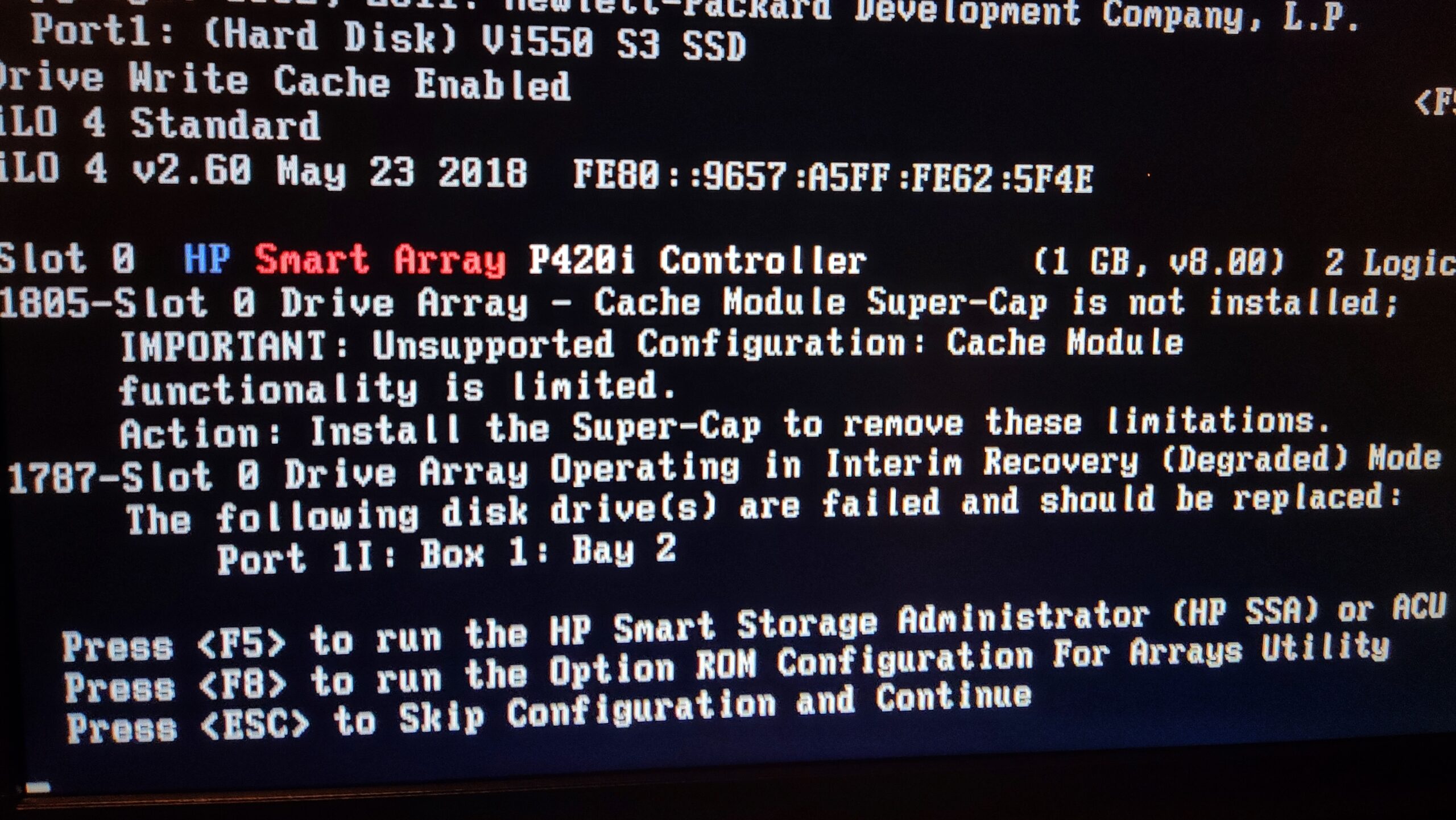
Originally I was going to replace a disk on my hardware controlled RAID 5. That didn’t work out well. The controller supports hot-plugging but the LED indicator stayed on faulty. To debug this I had to boot into the controller to check for the error message and lo and behold it appears my spare has an invalid block size and the controller is too dumb to format it with another, unlike e.g. sg_format.
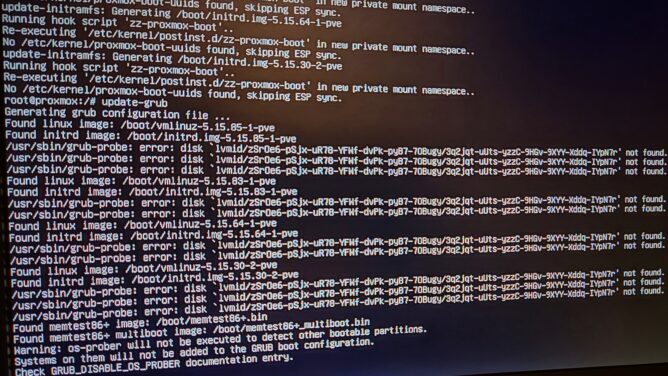
And this should have been the end of the story until I can reformat this on another SAS capable PC. Alas grub rescue greeted me on reboot with “error: disk `lvmid/foo/bar` not found.“
Turns out I was running into this rare bug https://bugs.debian.org/cgi-bin/bugreport.cgi?bug=987008 where the words “time-bomb” and “critical” are dropped. The gist is that grub has a bug that prevents it from reading LVM meta data sometimes and this results in a broken bootloader.
This is not fixed with the usual reinstall dance from another boot-able medium. The trick is to manipulate the LVM meta data in some way, e.g. by adding another volume temporary.
This means running a vgscan after booting from another medium and *in my case executing* e.g. lvcreate -L 4M pve -n foo
The name doesn’t matter as it can be removed afterwards. Updating the initramfs should run without errors now and is a good indicator if this worked. Now it’s possible to reboot again.
The two problems have basically nothing to do with each other. It was just my lucky day to run into this sequence of chained issues during my free Saturday night 😩
Oh yeah, meanwhile the RAID recovered also. Another spare was added until I have time to take a closer look at the block size issue.